파이썬 bytes() 함수는 바이너리 데이터를 처리하는 데 유용한 함수 중 하나입니다. 이 함수는 다양한 자료형을 바이트 형태로 변환할 수 있어 네트워크 통신이나 파일 처리 등 다양한 상황에서 유용하게 쓰입니다. 이번 글에서는 bytes() 함수의 사용법과 활용 방안을 살펴보고, 주의할 점에 대해서도 함께 알아보겠습니다.
목차
파이썬 bytes() 함수란?
bytes() 함수는 파이썬에서 바이트 객체(byte object)를 생성하는 함수입니다. 파이썬에서 문자열은 기본적으로 사람이 읽을 수 있는 텍스트 데이터를 다루지만, 바이너리 데이터는 사람이 읽을 수 없는 0과 1로 구성된 데이터를 처리합니다. 이런 바이너리 데이터는 파일 입출력, 네트워크 프로토콜, 암호화 작업 등에서 많이 사용됩니다.
기본 사용법
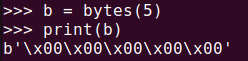
가장 기본적인 bytes() 함수의 사용 방법은 인자로 정수를 전달하는 것입니다. 이때, 해당 정수의 길이만큼 모든 값이 0인 바이트 객체가 생성됩니다.
b = bytes(5)
print(b)위 코드를 실행한 결과는 아래 그림과 같습니다. 길이가 5인 바이트 객체가 생성되었으며, 각 바이트 값은 모두 0입니다. \x00은 16진수로 0을 나타냅니다.
bytes() 함수에 다양한 자료형 적용하기
bytes() 함수는 다양한 자료형을 인자로 받을 수 있습니다. 가장 많이 사용되는 자료형과 그 적용 예시는 다음과 같습니다.
문자열을 바이트로 변환
문자열을 바이트로 변환할 때는 인코딩 방식을 지정해주어야 합니다. 가장 많이 사용되는 인코딩 방식은 ‘utf-8’입니다.
s = "Hello, こんにちは, 你好, 안녕"
b = bytes(s, 'utf-8')
print(b)문자열 “Hello, こんにちは, 你好, 안녕”는 utf-8 인코딩으로 바이트로 변환되었으며, 아스키코드에 해당하는 문자는 그대로 표현되지만 유니코드는 각 문자가 16진수 값으로 표시됩니다. 이처럼 텍스트 데이터를 네트워크나 파일로 전달할 때는 바이트로 변환하는 작업이 필수적입니다.

리스트나 튜플을 바이트로 변환
리스트나 튜플에 저장된 정수 값들을 바이트 객체로 변환할 수도 있습니다. 이때, 각 정수는 0에서 255 사이의 값을 가져야 합니다.
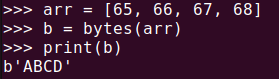
arr = [65, 66, 67, 68]
b = bytes(arr)
print(b)여기서 숫자 65, 66, 67, 68은 각각 ASCII 코드로 ‘A’, ‘B’, ‘C’, ‘D’에 해당하므로 바이트 객체는 “ABCD”로 출력됩니다.
바이트 객체를 문자열로 변환
바이트 객체를 다시 문자열로 변환할 때는 decode() 메서드를 사용합니다. 이때도 인코딩 방식을 지정해 주어야 합니다.
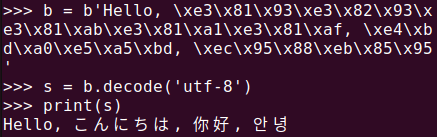
b = b'Hello, \xe3\x81\x93\xe3\x82\x93\xe3\x81\xab\xe3\x81\xa1\xe3\x81\xaf, \xe4\xbd\xa0\xe5\xa5\xbd, \xec\x95\x88\xeb\x85\x95'
s = b.decode('utf-8')
print(s)바이트 데이터를 원래의 문자열로 변환할 때는 decode() 메서드를 사용하는데, 반드시 원래 변환할 때 사용한 인코딩 방식과 동일한 방식을 사용해야 합니다. 아래 그림은 위의 그림 2에서의 변환 과정과 반대로 바이트 객체가 문자열로 변환된 결과입니다.
파일 입출력에서 bytes() 사용하기
바이너리 파일을 읽거나 쓸 때 bytes()를 자주 사용하게 됩니다. 예를 들어, 이미지를 바이너리 모드로 읽어서 파일로 저장하는 경우, 데이터를 바이트로 처리해야 합니다. 바이트로 처리하기 위해서는 ‘rb’ 또는 ‘wb’와 같이 문자 b가 들어가야 합니다.
with open('input_image.jpg', 'rb') as f:
data = f.read()
with open('output_image.jpg', 'wb') as f:
f.write(data)위 예제에서는 input_image.jpg 파일을 읽어 바이트 데이터를 가져온 후, 그대로 output_image.jpg로 다시 저장합니다. 이 과정에서 파일은 텍스트 모드가 아닌 바이너리 모드로 열려 처리됩니다.
바이트 객체와 배열
bytes() 함수로 생성된 바이트 객체는 변경이 불가능한(immutable) 특성을 갖습니다. 만약 변경 가능한 바이트 배열을 원한다면 bytearray() 함수를 사용할 수 있습니다.
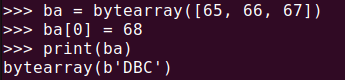
ba = bytearray([65, 66, 67])
ba[0] = 68
print(ba)bytearray()는 bytes()와 거의 유사하지만, 생성된 배열을 수정할 수 있다는 차이점이 있습니다. 바이너리 데이터를 다룰 때 변경이 필요한 경우라면 bytearray()를 사용하면 좋습니다.
주의사항: 인코딩과 디코딩
바이트 객체를 문자열로 변환하거나 반대로 문자열을 바이트 객체로 변환할 때는 반드시 인코딩 방식을 일관되게 사용해야 합니다. 서로 다른 인코딩 방식을 사용할 경우 데이터가 손상되거나 변환에 실패할 수 있습니다.
예를 들어, utf-8로 인코딩한 바이트 객체를 ascii로 디코딩하려 하면 에러가 발생합니다. 이러한 문제를 방지하기 위해서는 처음 인코딩한 방식과 동일한 인코딩을 사용하여 디코딩해야 합니다.
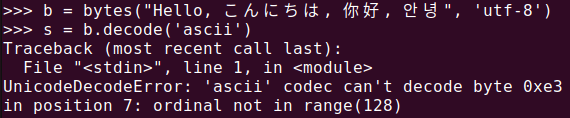
b = bytes("Hello, こんにちは, 你好, 안녕", 'utf-8')
s = b.decode('ascii')위와 같이 bytes 객체로는 utf-8 인코딩을 했는데, ascii로 디코딩을 하려고 하면 아래와 같이 “UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe3 in position 7: ordinal not in range(128)”이라고 아스키 코드 범위 안에 0xe3이 없으므로 디코딩 할 수 없다고 알려줍니다.
정리
파이썬 bytes() 함수는 문자열, 리스트, 튜플 등 다양한 자료형을 바이트로 변환할 수 있으며, 이를 통해 파일 입출력, 네트워크 통신, 암호화 작업 등에서 중요한 역할을 합니다. 특히, 문자열과 바이트 객체 간의 변환 시 인코딩 방식을 일관되게 사용해야 한다는 점이 중요합니다. 또한, 바이트 객체는 수정할 수 없는 특성을 가지지만, bytearray()를 사용하면 수정 가능한 배열을 생성할 수 있습니다. bytes() 함수는 다양한 활용 가능성을 가지고 있으므로, 이를 잘 활용하면 효율적인 데이터 처리가 가능합니다.