Python bytes()関数は、バイナリデータを処理する際に便利な関数の一つです。この関数は、さまざまなデータ型をバイト形式に変換することができ、ネットワーク通信やファイル処理など、さまざまな場面で役立ちます。この記事では、bytes()関数の使い方とその活用方法について説明し、注意すべき点も一緒に見ていきます。
目次
Python bytes()関数とは?
bytes()関数は、Pythonでバイトオブジェクトを生成する関数です。Pythonの文字列は通常、人が読めるテキストデータを扱いますが、バイナリデータは人が読めない0と1で構成されたデータです。このようなバイナリデータは、ファイルの入出力、ネットワークプロトコル、暗号化作業などで頻繁に使用されます。
基本の使い方
bytes()関数の最も基本的な使い方は、引数に整数を渡すことです。このとき、指定された長さだけのすべての値が0のバイトオブジェクトが生成されます。
b = bytes(5)
print(b)上記のコードを実行すると、以下の図のような結果になります。長さ5のバイトオブジェクトが生成され、各バイト値はすべて0です。\x00は16進数で0を表します。
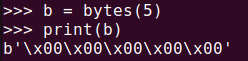
bytes()で5バイト長のバイトオブジェクトを生成bytes()関数にさまざまなデータ型を適用する
bytes()関数は、さまざまなデータ型を引数として受け取ることができます。最も一般的に使われるデータ型とその適用例は次の通りです。
文字列をバイトに変換
文字列をバイトに変換する場合、エンコーディング方式を指定する必要があります。最も一般的に使用されるエンコーディング方式は「utf-8」です。
s = "Hello, こんにちは, 你好, 안녕"
b = bytes(s, 'utf-8')
print(b)文字列”Hello, こんにちは, 你好, 안녕”はutf-8エンコーディングでバイトに変換され、ASCIIコードに該当する文字はそのまま表示されますが、Unicodeは各文字が16進数値で表示されます。このように、テキストデータをネットワークやファイルに渡す際には、バイトに変換する作業が必要不可欠です。

bytes()で英語、日本語、中国語、韓国語をバイトオブジェクトに変換リストやタプルをバイトに変換
リストやタプルに保存された整数値をバイトオブジェクトに変換することもできます。このとき、各整数は0から255の範囲内でなければなりません。
arr = [65, 66, 67, 68]
b = bytes(arr)
print(b)ここで、65, 66, 67, 68という数字は、それぞれASCIIコードで「A」、「B」、「C」、「D」に対応するため、バイトオブジェクトは「ABCD」と出力されます。
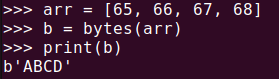
bytes()でリストをバイトオブジェクトに変換バイトオブジェクトを文字列に変換
バイトオブジェクトを再び文字列に変換する場合は、decode()メソッドを使用します。この際もエンコーディング方式を指定する必要があります。
b = b'Hello, \xe3\x81\x93\xe3\x82\x93\xe3\x81\xab\xe3\x81\xa1\xe3\x81\xaf, \xe4\xbd\xa0\xe5\xa5\xbd, \xec\x95\x88\xeb\x85\x95'
s = b.decode('utf-8')
print(s)バイトデータを元の文字列に変換する際には、decode()メソッドを使用しますが、必ず最初に変換した際に使用したエンコーディング方式と同じ方式を使用しなければなりません。以下の図は、前述の図2の変換プロセスを逆にして、バイトオブジェクトが文字列に変換された結果です。
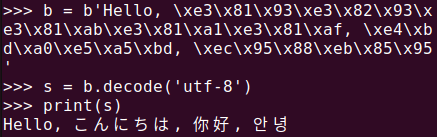
bytes.decode()メソッドで文字列に変換ファイル入出力でbytes()を使う
バイナリファイルを読み取ったり書き込んだりする際に、bytes()は頻繁に使用されます。例えば、画像をバイナリモードで読み取り、ファイルに保存する場合、データをバイトとして処理する必要があります。バイトで処理するためには、rbまたはwbのように文字bを含める必要があります。
with open('input_image.jpg', 'rb') as f:
data = f.read()
with open('output_image.jpg', 'wb') as f:
f.write(data)この例では、input_image.jpgファイルを読み取ってバイトデータを取得し、それをそのままoutput_image.jpgに再び保存しています。このプロセスでは、ファイルはテキストモードではなくバイナリモードで開かれ、処理されます。
バイトオブジェクトと配列
bytes()関数で生成されたバイトオブジェクトは、変更不可能(immutable)な特性を持っています。もし変更可能なバイト配列が必要な場合は、bytearray()関数を使用することができます。
ba = bytearray([65, 66, 67])
ba[0] = 68
print(ba)bytearray()はbytes()とほぼ同様ですが、生成された配列を修正できるという違いがあります。バイナリデータを扱う際に、変更が必要な場合は、bytearray()を使用するとよいでしょう。
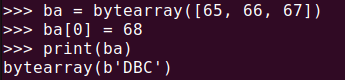
bytearray()を使用するとバイナリデータを変更できる注意事項: エンコーディングとデコーディング
バイトオブジェクトを文字列に変換したり、逆に文字列をバイトオブジェクトに変換する際には、必ずエンコーディング方式を一貫して使用する必要があります。異なるエンコーディング方式を使用すると、データが損傷したり、変換に失敗する可能性があります。
例えば、utf-8でエンコードされたバイトオブジェクトをasciiでデコードしようとすると、エラーが発生します。このような問題を防ぐためには、最初にエンコードした方式と同じエンコーディング方式でデコードする必要があります。
b = bytes("Hello, こんにちは, 你好, 안녕", 'utf-8')
s = b.decode('ascii')上記のように、bytesオブジェクトはutf-8でエンコードされていますが、asciiでデコードしようとすると、次のようなエラーが発生します。
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe3 in position 7: ordinal not in range(128)
このエラーは、アスキーコードの範囲内に0xe3が含まれていないため、デコードできないことを示しています。
bytes()オブジェクト生成時に使用したエンコーディング方式をデコード時に適用しないと発生するUnicodeDecodeErrorまとめ
Pythonのbytes()関数は、文字列、リスト、タプルなど、さまざまなデータ型をバイトに変換でき、それを通じてファイル入出力、ネットワーク通信、暗号化作業などで重要な役割を果たします。特に、文字列とバイトオブジェクトの変換時には、エンコーディング方式を一貫して使用することが重要です。また、バイトオブジェクトは変更できない特性を持ちますが、bytearray()を使用すれば、変更可能な配列を生成することができます。bytes()関数は、多様な活用方法があるため、これをうまく利用すれば効率的なデータ処理が可能です。